Image
Postman is a convenient tool that can describe and execute requests, receive information about their statuses, build chains of requests, loop them, and create scripts. The main advantage is that you almost do not need to write any code at all.
Some time ago, we already talked about the technology by which we put products on monitoring. At the top level, the plan is as follows:
Postman is responsible for the last step in this process, and even an engineer with zero experience and no knowledge of the code can actually use it. We have checked: in order to learn how to make scripts in this program, one only needs a couple of hours. After that, the support specialist can independently prepare new requests, schedule them, and monitor the results.
How to work with Postman
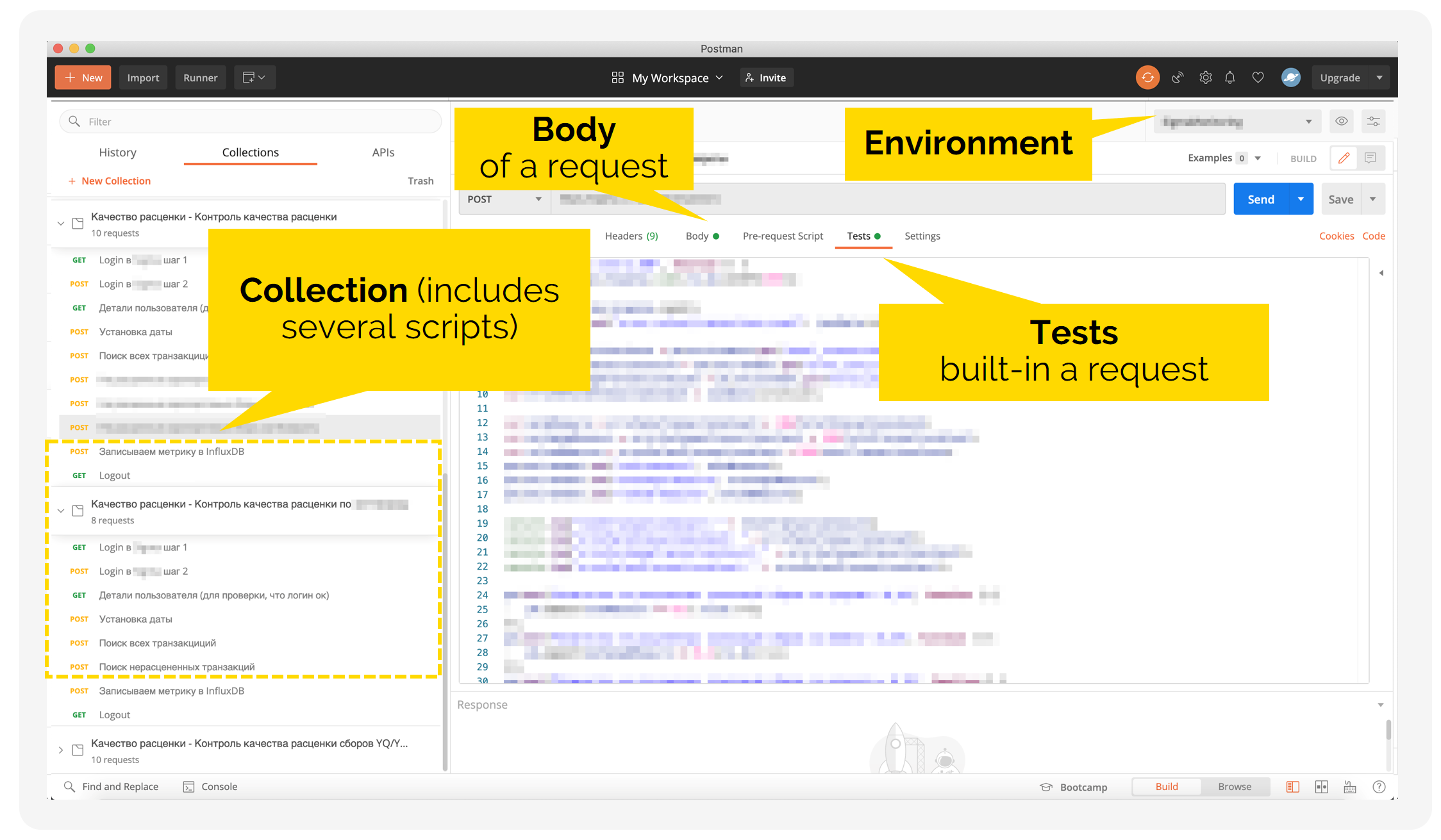
So, you have made a decision on the scenarios to be monitored, and prepared a list of requests that correspond to user actions. In Postman, scripts are collected from these requests, as from a construction toy. In addition to requests, the collections and environments play the part of the building pieces.
Thus, the plan is as follows: write a request, save it to the collection, select the desired environment and go! If necessary, you can immediately add tests to be performed in each request or at each monitoring step. Our task is to make sure that the system checks the modules performance on a scheduled basis, so in this case, we did without additional tests.
How we built Postman into our process
We use Postman to develop monitoring scenarios, testing, and integration interaction.
Summary
When we were working on the monitoring technology, we planned to use Zabbix. On closer inspection, it turned out that it is not suitable for our purposes – it is impossible to write a script with native tools, and we had to prepare them in Python. Without such a tool as Postman collections, you have to do it again every time.
Here, all the logic is built into the interface. So it is enough for an engineer to substitute the necessary data in separate sections of the code. This significantly reduces the entry threshold for anyone who needs to work with requests; whether they are developers, analysts, testers, or anyone else.
The result is that support becomes more reliable, regardless of how fluent a particular engineer is in the code. At the same time, it is easy to transfer experience from team to team and there are no compromises in terms of the quality of processes.