The team leader’s objective is to ensure that his or her team works smoothly and productively. This is a tall order since there is no ready-made recipe for success. Of course, there some successful methodologies do exist out there, such as Agile, Lean, Value Stream and Mapping. These offer general guidelines and values, which is all well and good, yet these are merely guidelines and when it comes down to any sort decision-making, sorry buddy, you're on your own. That is what necessitates your position as a team leader in the first place.
In this article, our team leader will tell you how his team has gradually molded an approach to effective teamwork, which he now regularly refines. The key point is that the selected tools are truly accepted by the entire team and have been well utilized in the workplace. This gives hope that the selected approach will be fruitful.
A little bit of context
Within the team we will be talking about, we are working on making a huge, long-term product. Our specific team has seven people: four developers, one team/technical leader (writes code – a lot of code), one QA, and one PM. The product that the team is working on is two years old. Its technical condition (thanks to the efforts of the entire team) is near exemplary.
Discomfort As a Diagnostic Tool
To identify and understand the problems that exist within a team, we use a fairly simple tool: the team members’ discomfort.
Of course, we are not talking about situations in which one person feels too hot while another person is freezing with the air conditioner on. What I am talking about is disruptions in the normal workflow.
For instance, suppose the release goes awry, even though each individual did their job well. Or stabilization has already been going on for two weeks and the team is too overstretched, despite that we performed the evaluation ourselves and there was no one in our way for us to do well. Or the business didn't achieve the results it expected.
What to do in such a situation:
- Stop panicking and understand why people are currently feeling uncomfortable.
- Get to the root cause. For example, using the "Five Why's" technique, or simply common sense.
- Decide on the right way to handle the problem. At the end of this article, we will discuss guidelines for choosing a suitable solution. On that note, I will introduce a fundamentally important point: we use discomfort to diagnose problems, but this doesn’t mean that the reference point for choosing a solution is achieving comfort. Remember, the main reason that you exist as a team is to build business value. No one needs a happy team that doesn't achieve any results.
- After a while, look at matters from a retrospective perspective. If the solution you came up with did not help, we must revert back to point 1 with a new understanding. If that did help, we automate it or add it to the list of principles for future beginners. No control is necessary for the event the participants themselves accept the chosen approach and get it to work when the solution is actually good.
The given algorithm is simple; however, it is not specific enough. Next, I will describe the principles we have derived using this approach. So that the article doesn’t turn into a memoir, I will describe only the result, not the entire story from the time that the pain was first experienced to the time it was eliminated.
The principles we build the process on
1. We are constantly creating and shortening feedback loops
All human interaction with the outside world is built on feedback. Without feedback, it is impossible to check the correctness of the action performed. Imagine what our lives would be like if we didn't feel any pain after doing a four-meter high jump or grabbing onto a red-hot kettle.
In terms of development, an example of a good, short feedback loop is code completion: that tells us if the action is correct right at the moment we are typing.
Now for an example of not having a feedback loop: we know of a user problem, but we cannot reproduce it, we don’t have any logs, there is no way to quickly roll out a fix, and we don’t know what version is currently under production. I wouldn’t wish that on my worst enemy.
Every action in the development process can and should provide feedback: builds, lint, past autotests, testing conducted, test sessions with a business, successful deploys, and production monitoring: all these are ways to detect errors and adjust your further actions accordingly.
It is also worth noting that the cost of error increases the further we advance. If we happen to release a bug during production that spoils the data, not only will it have to be fixed, but the data will have to be restored as well (if that’s even possible). The cost of the late elimination of such an error is very high, not to mention the consequences for the business.
Therefore, having a large number of quick, informative feedback loops is vital.
Below are the loops that we consciously maintain and shorten when possible. I suppose you are familiar with most of them. But do you actually have them running and are they actually working?
- The ability to start and debug the project locally
- Development in accordance with the Fail Fast principle
- Fast, informative CI-build
- Constant code review and code operation through pull requests
- Autotests: the tests are fast and stable and the error messages – informative
- Automatic deploy because manual deploy wouldn’t be performed as often
- Frequent releases rather than accumulating all the development and releasing a version weeks after completing the tasks
- Informative logs, monitoring, and diagnostic tools, to which the whole team has access
- The ability to filter and graphically render the log
- Continuous monitoring of the system’s technical and functional indicators as daily tasks
- Empirical study of the system: Google Analytics and analysis of the data accumulated in the system
- Storing the data change history instead of the final condition, if applicable
- Close, collaborative work between developers, Ops, QA, and the business instead of "throwing the results over the fence" of the previous stage
- Conducting regular back observations both within the team and with the business
- Regular business feedback. Feedback from the end user would be even better
- The ability to observe the users’ work "in the field"
- The ability to observe users seeing your system for the first time
In general, feedback must be obvious. For example, a broken build.
What is remarkable is sometimes a very small change is enough to cause radical improvement.
For example, you write logs in ELK. They are structured, analyzed, publicly available, and everything is great. But does the developer check it often while debugging? He most likely does not.
If you output messages of the level warning and higher directly to the IDE, you get a chance to notice a problem with requesting performance time for example. Even if it is not related to the current task. You get a chance to notice the problem earlier and the cost of fixing it will be lower.
2. Any activity leaves publicly accessible artifacts
Artifacts must be available to the public. And they should come in handy too.
By operating based on this principle, we minimize the bus factor, provide a unified understanding of the situation and we work (and mess things up) consciously while constantly making conclusions.
Some practices are obvious and generally accepted: informative messages on commits, links between commits and tasks, How to Test descriptions, and Definitions of Done.
There are also less obvious points:
- You cannot "just screw it up" – the failure must be implemented. If the analysis reveals poorly thought-out requirements, the artifact will be the refinements that everyone recognizes. If the problem is the architecture of the system, the described technical debt with a clear deadline for the work being accepted will become the artifact.
- The amount of knowledge in mail, messengers, and heads should be minimal. All refinements are reflected in the knowledge base or the task tracker. That way, when a tester accepts a task, the modified requirements will not be something new to them. When the business accepts the result, everyone understands what they are supposed to get. This state turns the work into a continuous stream. Providing that (to find out the details, to update the knowledge base and the task descriptions) is a task that each participant of the process must accomplish.
- The test results are not just a matter of "Yeah, I checked and everything is okay” but a public list of passed test cases compiled and discussed before testing, and not during or after. The list can be studied and added to by each participant involved in the process.
3. We respect each other's right to undistracted work
The importance of working in a stream and the consequences of interruption, I believe, are already well known. Therefore, I will not delve far into the details of the problem but instead immediately dive into our practices.
- Working wearing headphones is all but encouraged.
- Work communication is asynchronous. Do not have your colleagues distracted by small questions. Ask it in the task tracker (see the public artifacts section).
- Sometimes things do happen that interrupt normal operation: an accident in production, unclear requirements for a problem which is already being worked on. The initiation of it can be a noisy discussion in the office involving three or more people. If such a situation is not resolved in a matter of a few minutes, I appoint one person to be responsible for clarifying the details of it. The rest will return to their normal working routine until the responsible person brings in the information for further analysis.
4. We avoid multitasking
This is because multitasking doesn't work. It only wears you out, spreads out your attention, and delays results.
What practices help:
- Limitation of Work In Progress.
- Focusing on the flow of value, not resources. For example, suppose one developer can complete a task in a day and the other can complete it in three. But the first will only be able to get to it in a week. Thus, the second one would be the best one to accept the task. We would spend more time implementing it, but we would deliver the result faster (in three days instead of a week and one day) and move onto the next task. At the same time, we try to not "cram it into" the first developer’s responsibilities and we do not get distracted by pending work while waiting for that developer.
- If several people are performing the same task, and the work is 90% complete, then the number one goal for the team is to do everything to finish the final 10%. Only after that do we move on.
5. We make architectural decisions as late as possible
This is not a matter of our know-how but a matter of the basic principles of lean production.
The decision made and has already implemented limits on the possibility for further modifications. Thus, if that decision is made with incomplete information (and this is almost always the case), the chances of making a faulty decision are much higher.
If the decision is not accepted and this fact does not block the work or leads to exponential technical debt growth, it must be postponed, leaving the system ready for any decision to be made in the future when we finally have more information.
The basis of development is: we do not build "large" architectures before starting a project. Instead, we render the refactoring process safe (see the feedback loop section) and turn it into a natural component of the process.
Similarly, we do not try to guess future system requirements or build an all-around solution. The ability to safely refactor is more versatile because it allows you to make any changes you need to make in the future.
6. The code must be in working condition at any given time
Of course, this state is unattainable in the absolute. The system will periodically break down after changes are made. But that doesn’t mean that this characteristic should not be strived for.
When a breakdown represents a state of emergency rather than an ordinary norm, its causes are easy to find. This is usually the last commit. Therefore, it becomes clear who the person responsible is, so the necessary actions to eliminate the problem are clear, and it also becomes clear when we will manage return to a stable state.
The resulting confidence in the system presents a valuable opportunity to make a release at any time.
The second benefit is that we become more confident in making promises about the deadlines. If you divide the work into two phases: "development" and "stabilization", it is difficult to make a particular promise, since "stabilization" means working with problems of which we do not yet know. That means that we cannot accurately evaluate them.
If the stabilization goes seamlessly along with development and all the necessary tools are available to this end, the situation will be more predictable.
How we maintain continuous performance:
- The obvious: code review, autotests, and feature flags.
- Any changes are immediately deployed to the test environment. If something broke, fixing it "some time later" would not work: the QA’s operation will be blocked.
- Continuous flow testing immediately after tasks are completed, as long as the developer remembers the task and the code and makes the corrections quickly.
- We do not do the work in parts. If two people are needed to implement it, they will work in pairs, in a single branch: they pour the code into the main branch when it is completely ready and covered with tests.
- With delivery automation and immutable delivery artifacts that do not need to be completed manually.
- Each team member knows the diagnostic tools, how to operate them, and how to make releases.
7. We are a team, not a group of developers
The definition of "team":
- All the code is reviewed by at least one person. If a serious problem is identified, it is encouraged to sit down together and perform programming in pairs. Sharing a book, an article, or a detailed explanation instead of broadcasting a personal opinion is priceless.
- Instead of developing it in chunks with subsequent painful integration of the result, we work closely in pairs when necessary.
- We do not turn the reviewer into a tool for checking typos – we bring a clean, small pull request to the review.
- If the problem arises, we don't throw the baby out with the bathwater, but carefully hand over the QA, checking the happy path ourselves. We help QA understand what can be tested and how. We also help with passing borderline scenarios (for example, intentionally breaking the system).
- QA, in turn, studies the internal structure of the system, knows how to collect all the necessary details (logs, data status), and makes an extremely informative bug.
8. We cut the loose threads
In order to do the present work as efficiently as possible and with total focus, we eliminate the "debts" associated with the work we’ve already done:
- Tasks are put into production as quickly as possible. Only then do we consider them done.
- We continuously eliminate technical debt so that it does not grow to a large correction cost (weeks) and does not block work, ruining plans for the business functionality’s delivery.
- We do not start any tasks that we will just do “someday" and we delete inactive tasks. Business will come to complete the task when (and if) the time to do it really comes. And, just in case, you can restore a deleted task in the task tracker. But this function has never been of use to us.
- Inactive branches, commented-out code, To-do lists – all of these is dead code, and the trash bin is where they belong.
- Unstable tests are immediately corrected or removed and replaced with lower-level ones.
- We track "lingering" tasks.
The last point is worth a separate explanation.
By "lingering" I mean the tasks with a low cost of labor, yet which have been pending and In-Progress for a number of days or weeks.
Why this may occur:
- The task is poorly worked out initially, has already required many clarifications, or clarifications are contradictory or incomplete. So, we just stop wasting time, stop working on the task, and revert back to the description.
- The task is in a state of awaiting a result from someone. For example, a service from another team or a clarification from the business. We keep such tasks on notice and do not leave them unattended.
It is difficult to do this point. First and foremost, you need to be aware of the "lingering". Then, you need to make a strong-willed decision, take a step back, and return to detailing. This is difficult to do for the developer as time has already been spent. And, of course, such a decision will meet resistance from the business. But experience shows that this reduces the chances of a result being produced which will be welcomed neither by the team, nor the business, nor the users.
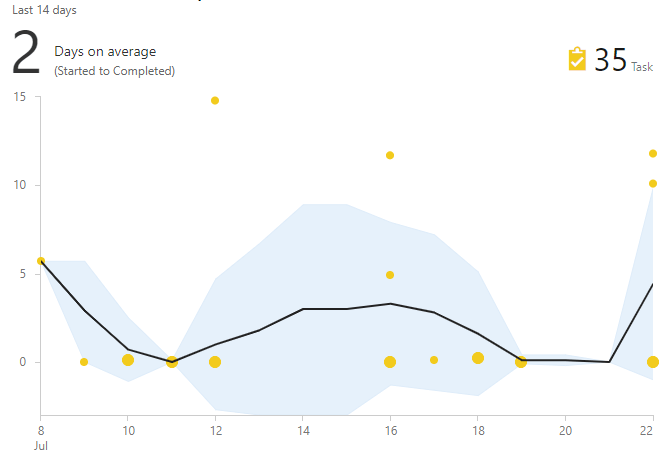
The cycle time chart helps in finding such tasks. It shows the time from the moment of the work was accepted to the moment that it is completed. If the task "stands out among the crowd", then it is a candidate for close study.
Choosing beneficial solutions
Unfortunately, I do not have a ready-made recipe on "how to" choose beneficial solutions. Team effectiveness is a heuristic problem, which means that it features no guaranteed solutions.
But there is still a checklist to review to guide you in the right direction. Here it is:
- I mentioned this at the beginning of the article and I will repeat it here: just because we use discomfort to diagnose problems doesn't mean we seek comfort in creating solutions. Remember, the main goal is to increase business value.
- When analyzing problems, remember that everybody involved has good intentions. If your thinking is based on the paranoid belief that someone is intentionally hurting you, then it is very difficult for a good decision to be made.
- Do not try to burn everything down and build it back up again. Take small steps in advancing, making the changes gradually. Wait until the changes you make yield results, and only then implement new ones.
- If there is no clear solution, then take in baby steps, constantly evaluating the result and trying out different options. A clear feedback loop and constant self-analysis are inexhaustible development tools for you and the team.
- Strike with the iron while it's hot. Do not delay analysis until hindsight – the team would already have forgotten what was happening. It is better to begin hindsight with the problem already understood and ready-made solutions so that the only thing left to do is to weigh them out with the team and choose the best one.
- The solution should be made by the entire team. No infringement "from above" will work, and any attempts to control are merely an illusion.
- Do not impose tasks on people if those tasks are atypical for their daily activities. You will be faced with a thousand plausible explanations as to why what was promised is not done, but you will not achieve the result.
- The effect of the solution should be tangible. You will rarely be able to formulate a solution on the characteristics of SMART, but some conscious methods for evaluating the result must exist. At least basing it on "now it doesn’t happen as often."
- Try to write down regularly what bit hurts the most from now on. If six months later you look back on the records with a smile, thinking "that was bloody rough", you are on the right track.
Conclusion
In conclusion, let's discuss the weaknesses that the approach entails.
First of all, this approach works when it comes to searching for local optimizations – it does not help build a product development strategy or a strategy for the company as a whole. Of course, problem awareness is better than blindly rumbling about and burning out at work, but this is only the first step.
Also, I ask of you, do not take a ready-made list of principles as your own but rather take the tool with which it was created. Here is why:
- Our list is incomplete. It only contains what we have already implemented within the bounds of our daily work.
- The team will not accept the principles until the importance of them becomes clear as a result of the pain of not having those principles. Instead of ideas put into action, you will get a bogeyman instead in that case – something that will be carried around the office for a while and then placed in the corner to collect dust.
- Our list is rather precise. For example, if the technical debt for a project has been ignored for five years and is comparable to the US national debt, it will be very difficult to benefit from the constant technical debt destruction principle. I have to be honest – a debt of this size will never be paid back. And focus on the solutions that will really help make the situation better.
But how do you improve the process? And what principles have you already adopted in within the bounds of your operation?