Image
In the beginning, we had a high-loaded monolithic solution to Microservices. 20,000-120,000 transactions daily, users across 12 time zones. We completely changed the product architecture without anyone of them noticing a thing.
Furthermore, newer and newer functions are constantly being added to it, which is quite difficult to bring to fruition on a monolith. For that reason, the system requires stable 24/7 operation, i.e. High-Load, High Availability, and High Fault Tolerance.
We are developing the product based on the MVP model. Its architecture has been modified at several stages to better suit our business needs. We were initially unable to do everything at once since nobody knew back then what the solution was supposed to look like. We moved forward with an Agile model, adding and expanding its functionality in iterations.
Under such circumstances, the main approach by which we began to allocate Microservices was the allocation of business functions or business services as a whole.
In this article, we will discuss the technical details of the project.
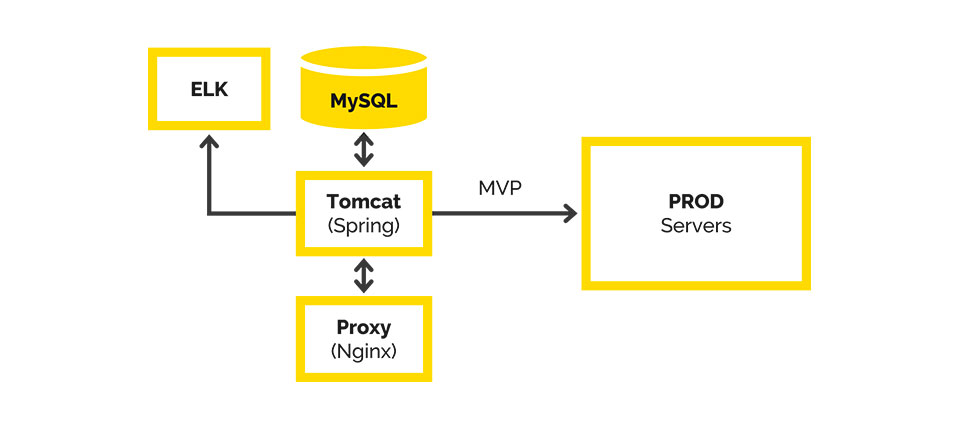
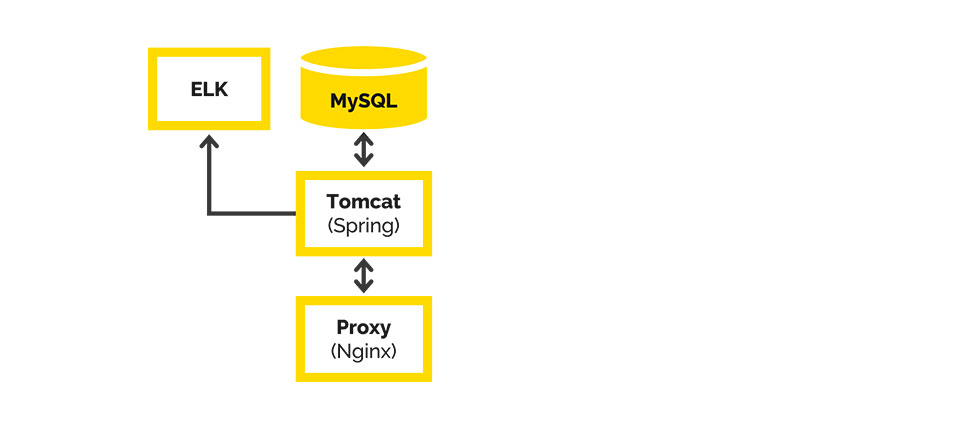
The original architecture included the following: we had MySql with nothing but WAR, Tomcat, and Nginx to proxy requests from users.
Environments (& minimal CI/CD):
Development was built based on user scenarios. As early as at the start of the project, most of the scenarios fit into some kind of workflow. However, still not all of them did. Thus, our development was complicated, and we could not carry out a "deep design".
In 2015, our app saw its way into production. Industrial usage has shown that the app lacks flexibility in its operation, development, and the way changes are sent to prod-servers. Our desire was to achieve High Availability (HA), Continuous Delivery (CD), and Continuous Integration (CI).
Here are the problems that we had to tackle in order to come to HI, CD, and CI:
We began tackling these problems one at a time. And the first thing that we set our sights on was changing the product’s requirements.
Challenge: Changing product requirements and new use cases.
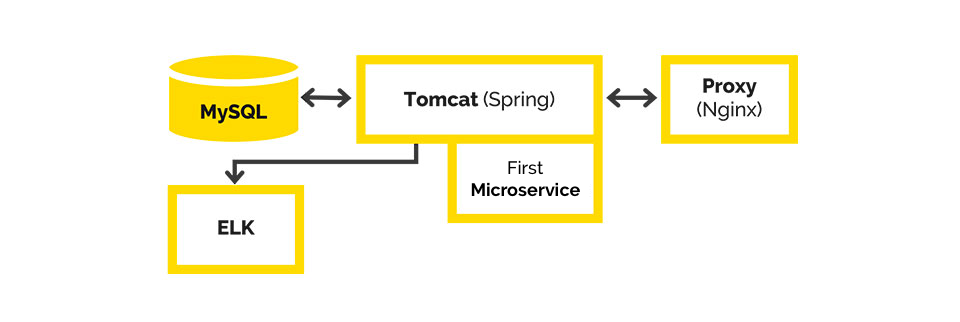
Technological response: the first Microservices was launched, we obtained part of the business logic in a separate WAR-file, and put it in Tomcat.
We received another "before the end of the week to update the business logic in the service" type task. We decided to take this part in a separate WAR-file and put it in Tomcat. We used Spring Boot for its configuration and development speed.
We devised a small business function that solved the problem with periodically changing user parameters. If the business logic changed, we wouldn't have to restart all of Tomcat and lose our users for half an hour, just to restart only a small part of it.
After successfully taking the logic based on the same principle, we continued making changes to the application. And from that moment on, when we received tasks that radically changed something within the system, we took those parts out separately. This way, we constantly accumulated new Microservices.
The main approach by which we began to allocate Microservices was allocating business functions or business services as a whole.
So, we quickly separated our services integrated with third-party systems, such as 1C.
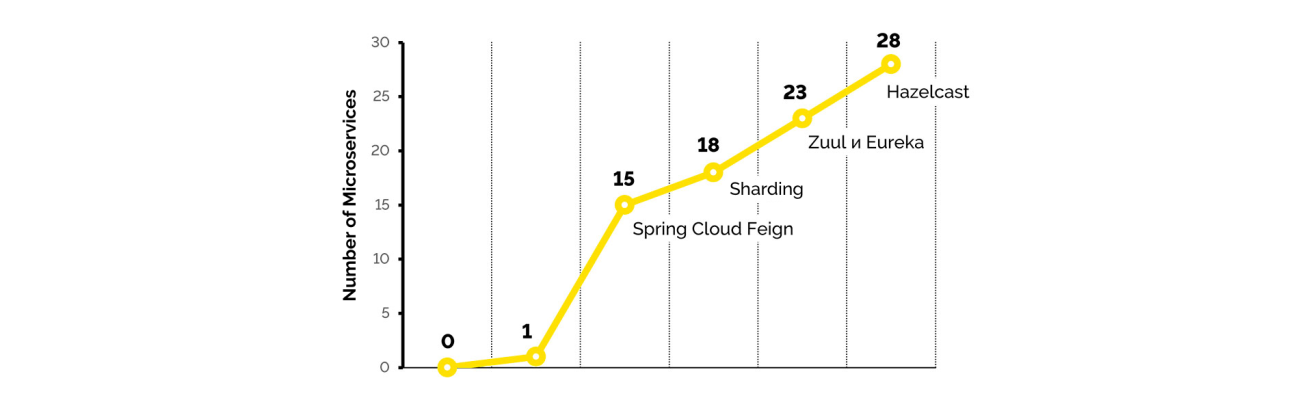
Challenge: the number of Microservices is already 15. The type-checking problem.Technical response: Spring Cloud Feign.
The problems did not go away on their own as a result of us merely cutting our solutions down into Microservices. Moreover, new problems began to arise:
New issues have prolonged the restart time of all of Tomcat during maintenance periods. It turned out that we have piled on the work that has to do.
The problem with type checking, of course, did not arise out of anywhere. Most likely, for several releases, we simply ignored it, since we discovered those errors as early as at the testing stages or during development and had time to do something about it. But when a few errors were identified as late as halfway through production and required urgent correction, we introduced regulations or started using tools that solved that problem. We turned our attention to Spring Cloud Feign, a client library for HTTP-requests.
The reasons we chose it:
It solved the type checking problem we had by helping us create our clients. And for our services’ controllers, we used the same interfaces as we did in forming the client. Thus, the type of checking problems was eliminated.
Business challenge: We achieved 18 Microservices; now downtime in the system is unacceptable.
Technical response: changes in the architecture and an increase in the number of servers.
We still had issues with downtime and rolling out new versions, and we still had a problem restoring Tomcat sessions and releasing resources. The number of Microservices that we had continued to grow.
The process of deploying all the Microservices took about an hour. From time to time, we had to restart the application due to a problem with Tomcat releasing resources. There was no easy way to do it quicker.
We started thinking about ways to change the architecture. Together with the infrastructure solution department, we built a new solution based on what we already had.
The following changes were made to the architecture:
Technologies used:
Thus, when a request came from the user to the services in Tomcat, they simply requested data from MySQL. Data requiring integrity was collected from all of the servers and glued together (all requests came through the API).
By applying this approach, we lost a little in consistency in the data, but we solved the problem we had been dealing with. The user could operate our app in any situation.
So, that is how we solved the major issues we were dealing with. The user experience downtime was gone. Customers no longer experienced any of that as we rolled out updates.
Business challenge: There were now 23 Microservices; data consistency issues
Technical solution: starting services separately. Improved monitoring. Zuul and Eureka. We simplified the development and delivery of individual services.
Problems kept popping up. This is what our redeploy looked like:
Having mulled it over, we decided that our issue would be solved by running services separately: if we start each service on its own rather than just on Tomcat, but each on its own, everything on one server.
But then other issues arose: how would the services communicate with each other and which ports should be opened outward?
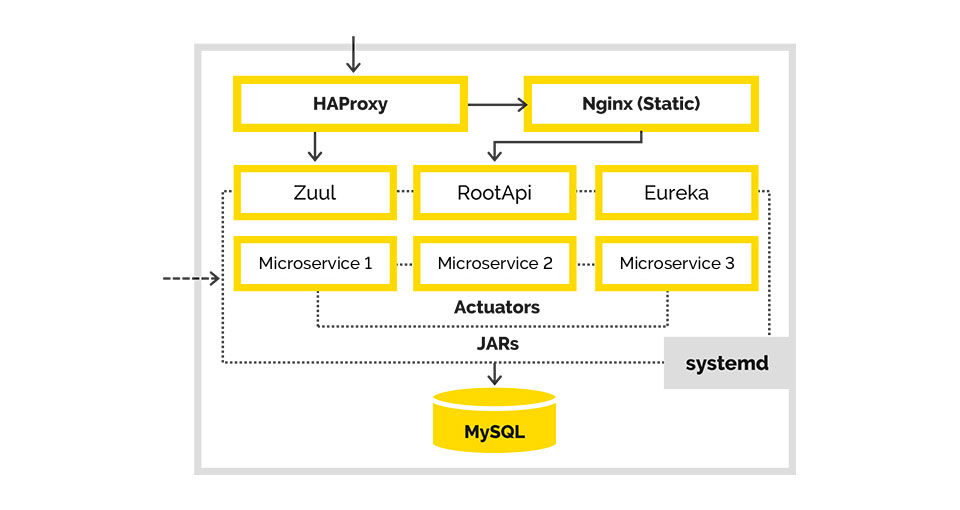
We selected several ports and distributed them to our modules. To avoid having to keep all the port information somewhere in a pom-file or general configuration, we chose Zuul and Eureka to take care of these tasks.
Eureka: service discovery
Zuul: proxy (to save contextual URLs in Tomcat)
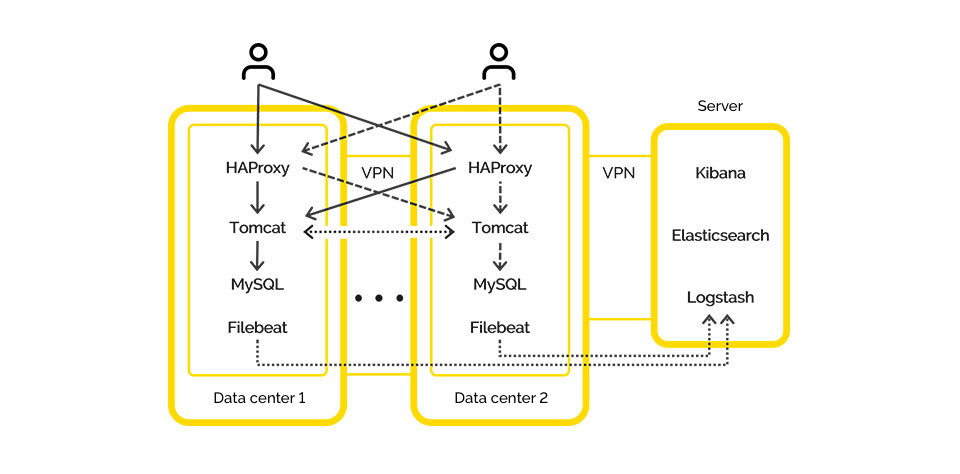
Eureka has also improved our performance in terms of High Availability/Fault Tolerance as communication between services has become possible. We have set it up so that if the current data center does not have the right service, you go to another one.
To improve monitoring, we added parts from the existing Spring Boot Admin stack to get a picture of what is happening on what service.
We have also started moving our dedicated services to the stateless architecture to eliminate issues in deploying several identical services on the same server. This provided us with horizontal scaling within a single data center. Inside a single server, we ran different versions of the same application when updating so that there was no downtime whatsoever.
We ended up approaching Continuous Delivery/Continuous Integration by simplifying the development and delivery of individual services. There was no longer any need to worry that the delivery of one service would cause a resource leak and that we would have to restart the entire service.
Downtime remained when we’d roll out new versions, but not to the same extent. When we updated several jars on the server one by one, the process would go quickly. And the server did not have any problems while updating a large number of modules. However, restarting all 25 microservices during an upgrade took quite a long time indeed, despite that it did so faster than in Tomcat, which does it consistently, step by step.
The problem with the releasing resources was also solved by starting everything with jars, and leaks or issues were dealt with by the system Out Of Memory Killer.
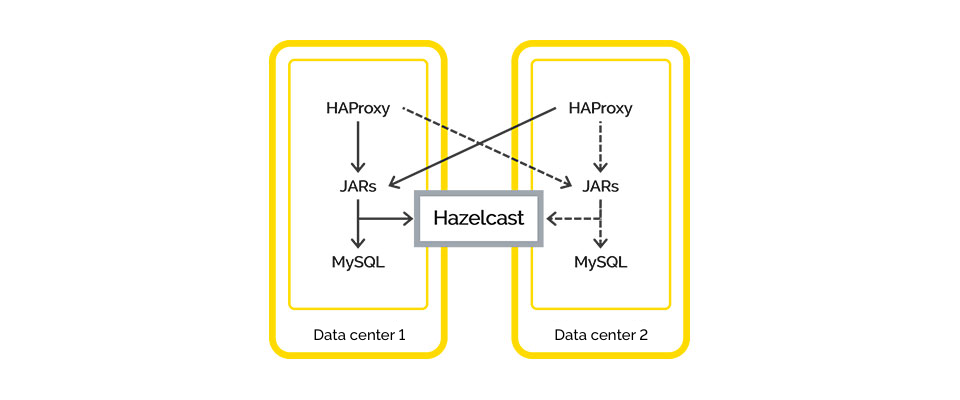
Business challenge: 28 microservices. There is a lot of information that you have to control.
Technical solution: Hazelcast.
We continued implementing our architecture and realized that our core business transaction utilizes multiple servers at once. It was inconvenient for us to send a request to a dozen different systems. Therefore, we decided to use Hazelcast for event-messaging and system operation with users. Furthermore, for subsequent services, it was used as a layer between the service and the database.
We finally eliminated our data consistency issue. Now we could save any data to all databases at the same time, without having to perform any unnecessary actions. We told Hazelcast which databases it should store incoming information in. It did so on every server, which simplified the work we had to do and allowed us to eliminate sharding.
And thus, we moved on to replication at the application level.
Also, now we began storing sessions in Hazelcast and using it for authorization. This allowed us to transfer users between servers without them noticing it.
Business challenge: we needed to speed up the release of production updates.
Technical solution: the deployment pipeline of our application GitFlow to work with the code.
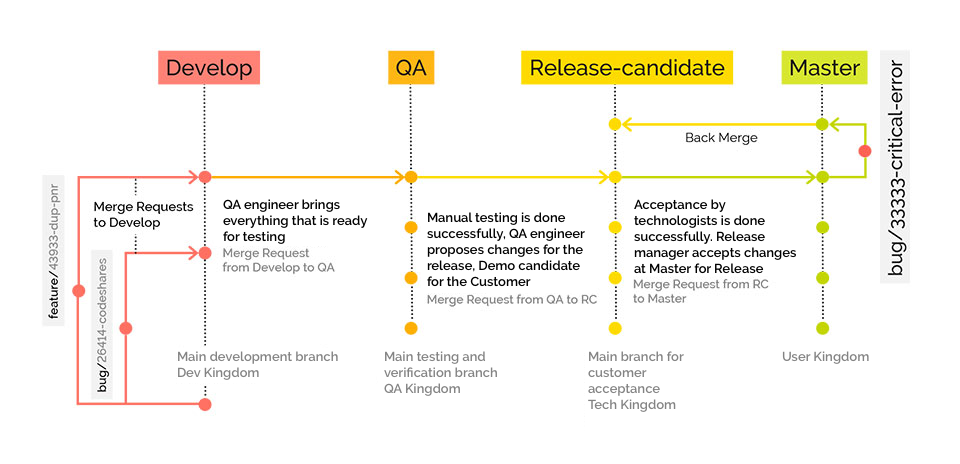
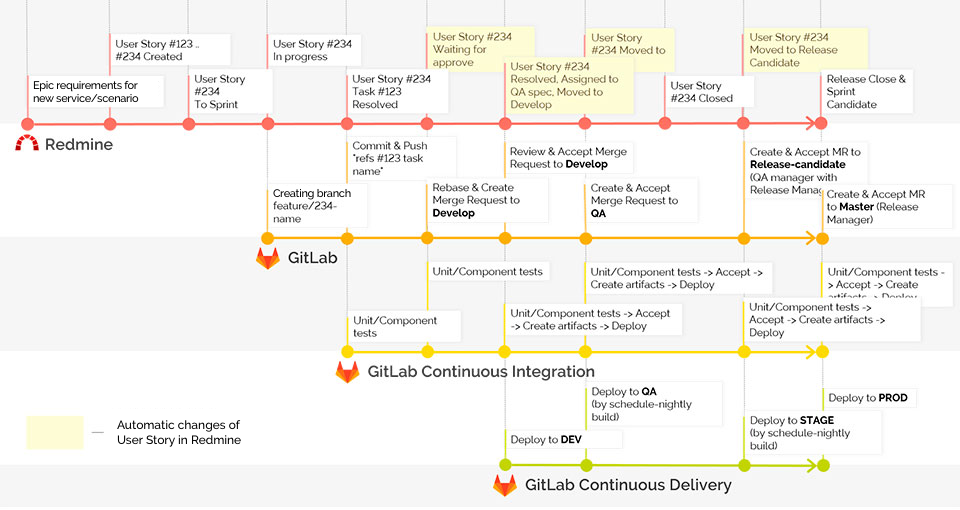
Along with the number of microservices, the internal infrastructure was developed as well. We wanted to speed up the delivery of our services to production. To do so, we implemented a new deployment pipeline for our application and moved to GitFlow to work with the code. CI began to collect and run tests for each commitment, run unit-tests, integrations, add artifacts to the delivery of the application.
To do this quickly and dynamically, we deployed several GitLab runners that ran all of these tasks on the developer push. Thanks to the Gitlab Flow approach, we obtained several servers: Develop, QA, Release-candidate, and Production.
Development goes as follows: the developer adds new functions in a separate branch (feature branch). After the developer has finished, they create a request to merge their branch with the main development branch (Merge Request to Develop branch). The merge request is checked by other developers and is either accepted or not, after which the correction work is performed. After merging into the main branch, a special environment is deployed, on which tests are performed for raising the environment.
When all these steps are complete, the QA engineer takes the changes to their "QA" branch and conducts testing on the previously written test cases for a feature and research testing.
If the QA engineer approves the performed work, then the changes are passed on to the Release-Candidate branch and are deployed to an environment that is accessible to external users. In this environment, the customer provides acceptance and verification of our technologies. Then we submit it all into Production.
If at some stage bugs are detected, then we solve these problems in these branches and merge them in Develop. We also made a small plugin so that Redmine could tell us at what stage the feature is at a given time.
This helps show testers what stage they are to connect to the task at, and developers what stage they are to correct bugs at, since they see the stage the error occurred at, and they can go to that particular branch and reproduce it there.
Business challenge: switching between servers without downtime
Technical solution: Packing in Kubernetes.
Now at the end of the deployment, technical specialists send JERs to PROD-servers and restart them. This is not very convenient. We wish to further automate the system by implementing Kubernetes and linking it to the data center, updating them and rolling them out at once.
To move to this model, we need to complete the following tasks:
What has changed in light of the transition to Microservices?