
Image
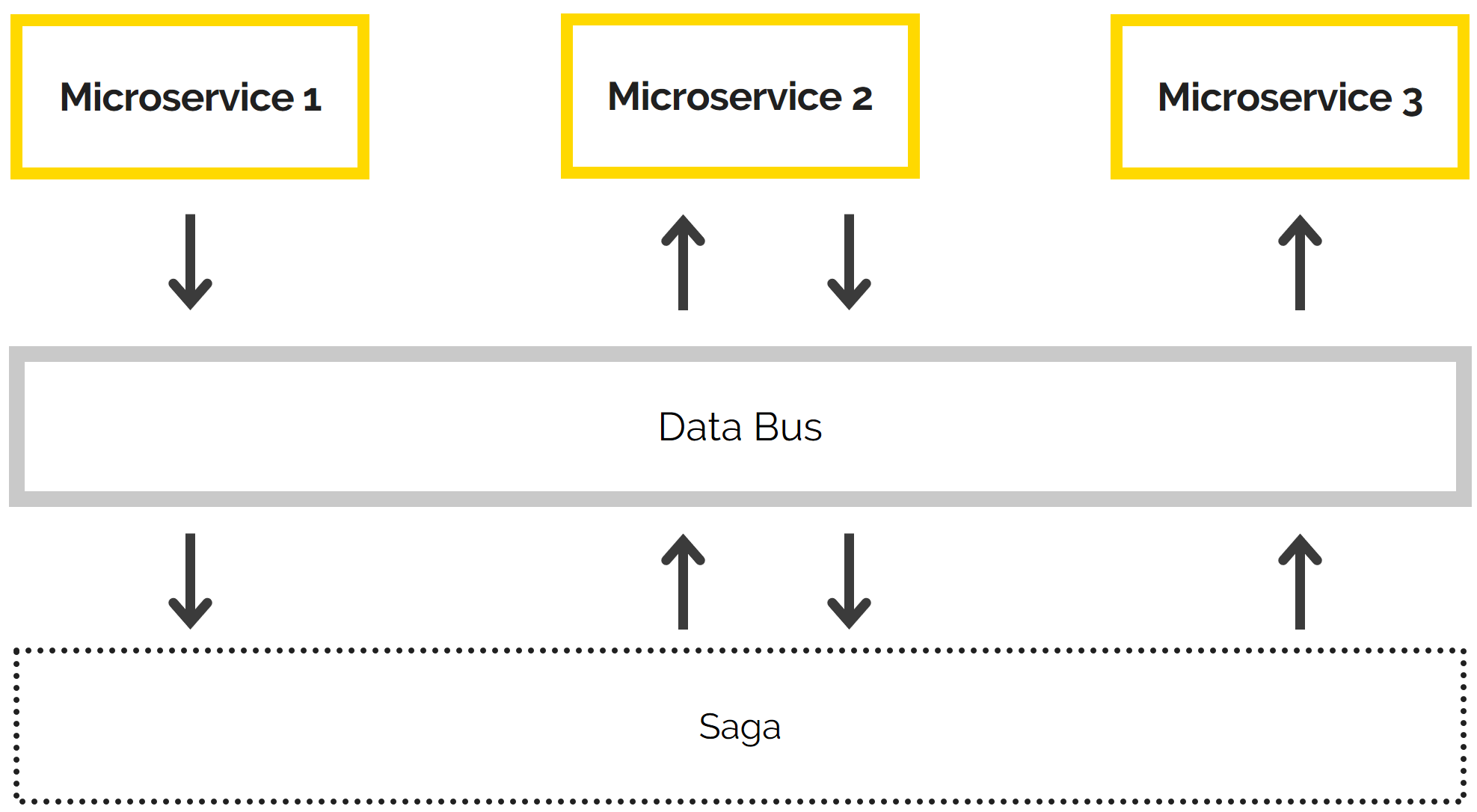
It is much more difficult to build sequential chains of operations in microservice products than in monoliths. Distributed transactions accompany the threat of data inconsistency, and developers have to figure out how to teach their microservices how to report their activity. Today, we discuss the Saga design pattern that we use to manage transactions within our products.
A monolithic application utilizes a single database, and each transaction has a beginning and an end. We are confident that the data of any multi-step process in such an architecture will be consistent.
When we switch to microservices, this confidence disappears. Each microservice works independently and saves its data to its own database, and these databases can be fundamentally different from each other. Operations are asynchronous in nature, and it is almost impossible to accurately control their activity within a multi-stage process.
A couple of examples of what the inconsistency of data can end up costing you
Consider the case of a banking application with the money transfer feature. This feature works on two microservices: one is responsible for withdrawing money from one account, and the other is responsible for transferring it to another account. If developers have not taken care of data consistency, a failure of one of the microservices or the bus-line through which they communicate can lead to the loss of money.
Another example is a large corporate product with complex internal logic. Let's take an electronic document management system: it accepts scans from the user, then sends some data to accounting, some to financial systems, and the documents themselves to an electronic archive, etc. Without distributed transaction control, all internal processes become a black box. If any errors occur, we don't have the option to stop and restart the process. We cannot partially upload the properly executed documents and return the rest to the user, it functions on an "all or nothing" basis.
To avoid those sorts of conflicts in a microservice product, and so that the data is not lost and remains consistent, we use the Saga design pattern.
How Saga Operates
Technically, Saga is a separate microservice that uses the bus-line to receive event messages sent from other microservices. There are two ways Saga functions:
This approach is used in both short-term and long-term processes, which may require many sequential actions, switching from system to system, and can last for several days.
Using Saga in our practice
Example 1: In the system that works with media files of the DAM (Digital Asset Management) type, users can upload dozens of photo and video files at a time, and each of them passes through several microservices as they are added.
Without Saga, users won't know when these files are available for further processing, and if the page freezes or updates, the download process is forced to restart.
Saga allows us to show users download progress, request additional data from them without having to interrupt the process, and cancel the download, if, for example, the system detects a wrong file has been attached by the user.
Example 2. In the system for business trip expense reports, employees sequentially enter various kinds of data and upload receipts and documents. Saga coordinates this entire process in full compliance with the company's internal regulations. The product architecture is built on a business process that would otherwise have to be completed offline. Therefore, the IT system works transparently for a business.
Alternative approaches, or why we chose Saga
Beside Saga, there are other approaches to managing distributed transactions.
Distributed transaction coordinator. This is similar to Saga, but instead of listening to the data bus-line, and sending messages to microservices through it, the orchestrator works directly with the microservices database.
Limitations:
Outbox-Inbox. Microservices exchange messages directly, without an orchestrator. If you go back to the example with the banking application, when transferring money, one microservice saves a message about sending in its Outbox, and the other one writes a message about receiving in its Inbox. If a failure occurs, you can compare their boxes and achieve data consistency.
Limitations:
This is where you should think about Saga.